
EM + Boostrap
- Tomson Qin
- Jun 12, 2019
- 2 min read
In a recent presentation, my group demonstrated the use of boostrap for EM missing data imputation. The EM algorithm makes estimates of the missing values, given the observed values and Bootstrap helps find the best hyper-parameters for EM by a robustness criteria.
The EM algorithm attempts to find the parameters of mixture distributions using an iterative algorithm. However, the number of clusters you choose to fit can result in significant difference in your results.




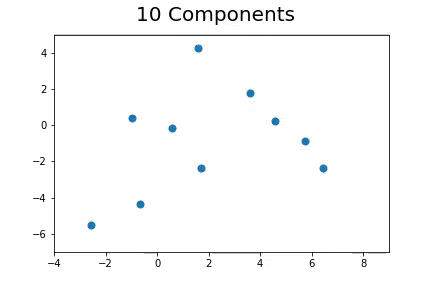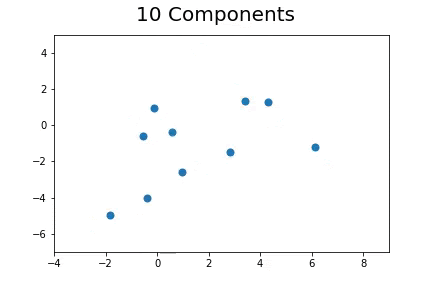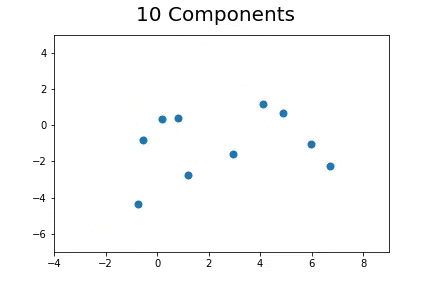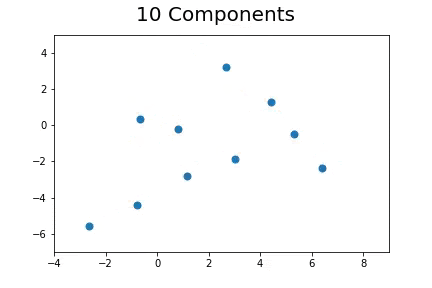
Using EM to assign the unlabeled points to N number of clusters:












Since our data was generated by 3 Normal Distributions, the other graphs demonstrate under and over fitting. So how can we determine the appropriate number of clusters to fit in real scenarios such as feature selection or in this case, missing data imputation?
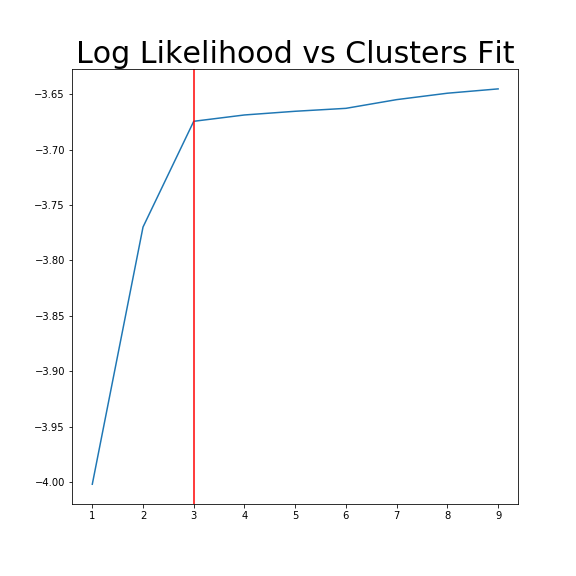
One way is by assessing the Log Likelihood vs Clusters fit. The more clusters fit, the higher the log likelihood, however we have a decreasing marginal rate of return. 3 clusters seems to be the point at which fitting more clusters gives very little improvement.

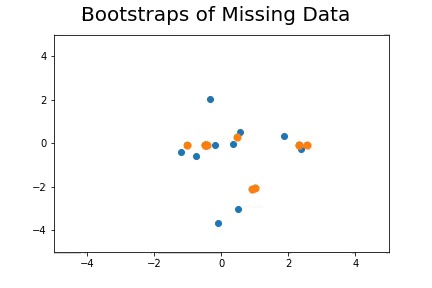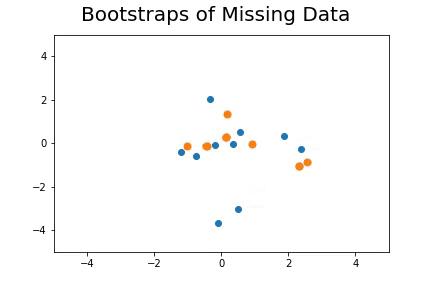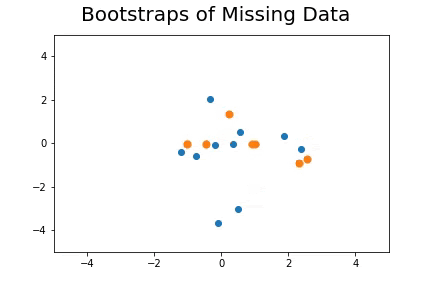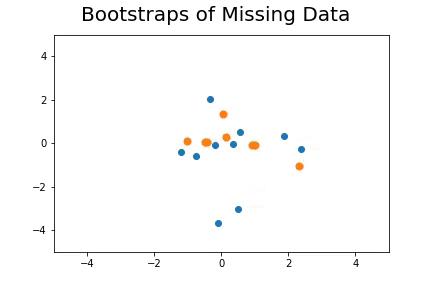
The second method, which is the method we described in our paper uses bootstrap to determine a measure of robustness. Below we applied bootstrap to the Gaussian data and applied EM to determine the cluster means and plotted them.
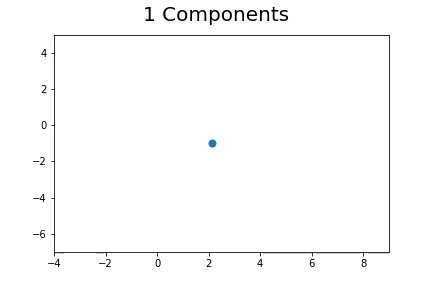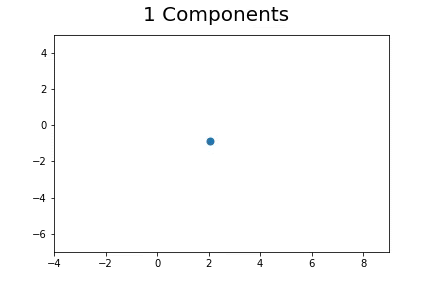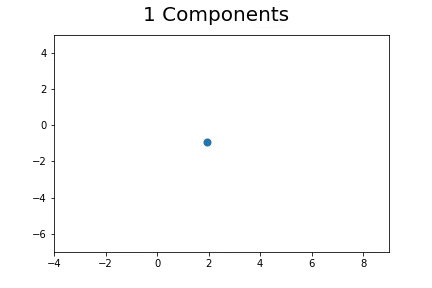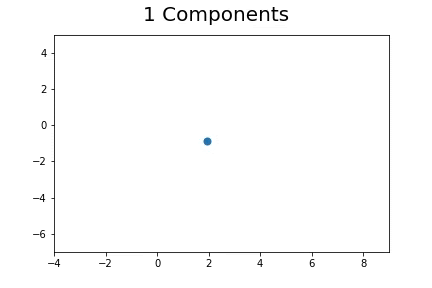
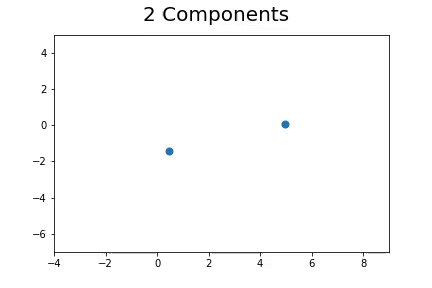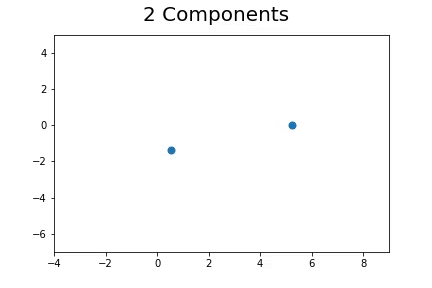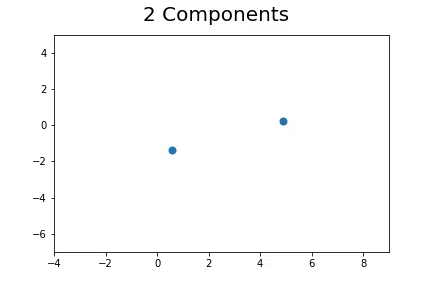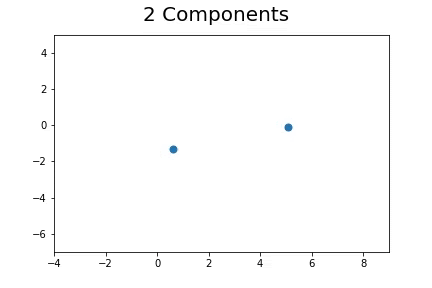
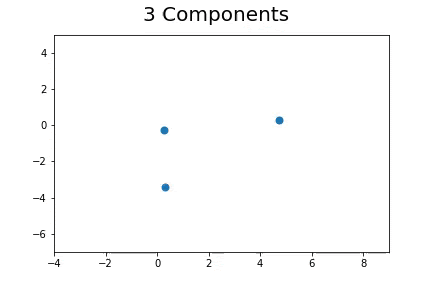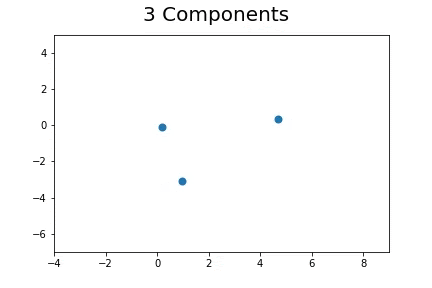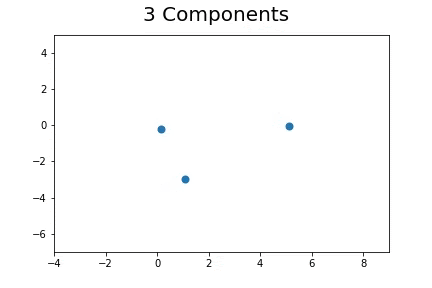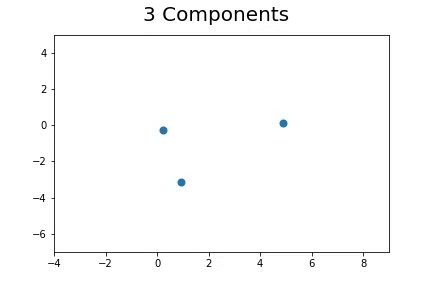
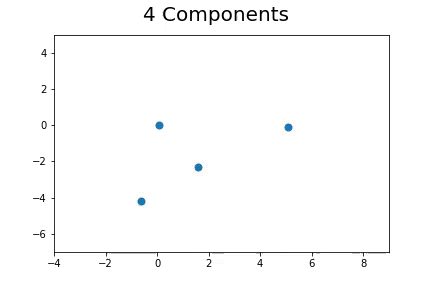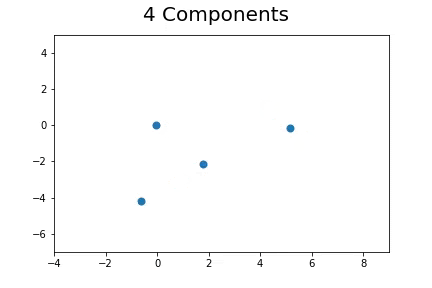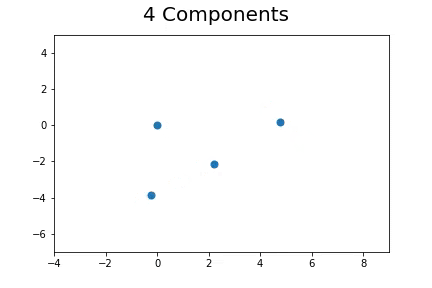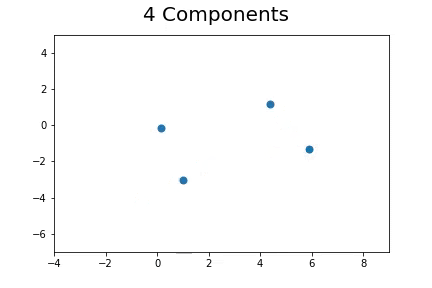
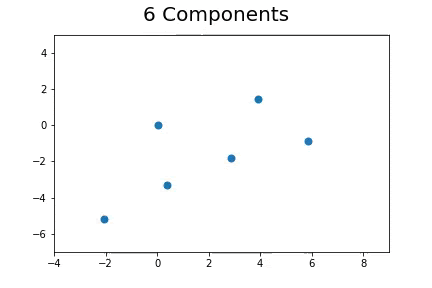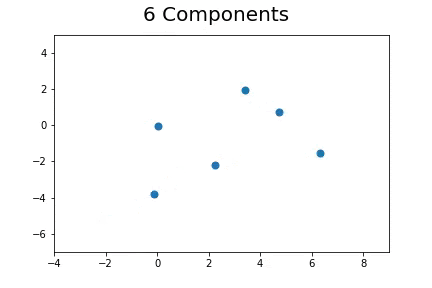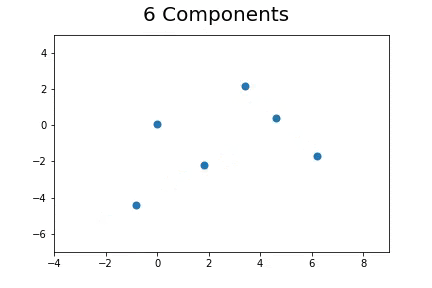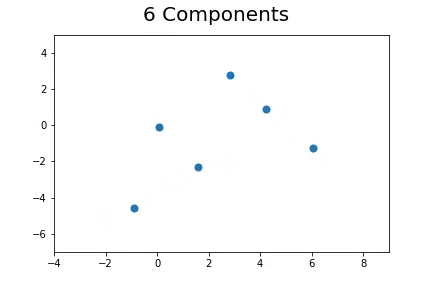
As you can see, the more clusters we fit the less robust (sensitive to small changes in data) our EM algorithm becomes.
Bootstrap datasets mimic the data. Well fit EM algorithms fit to the inherent structure of the data that is persistent across bootstrap samples whilst over fit EM algorithms fit to the noise from the bootstrapping process.
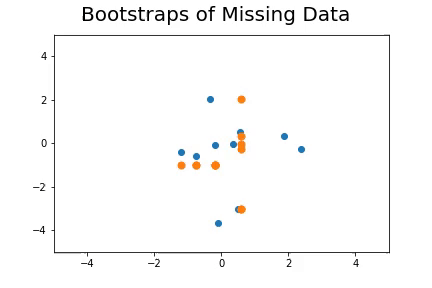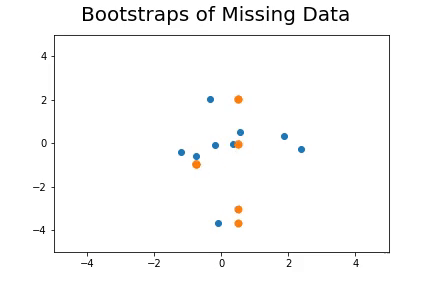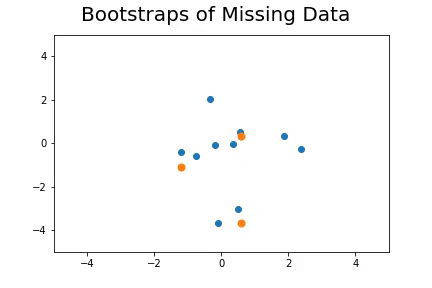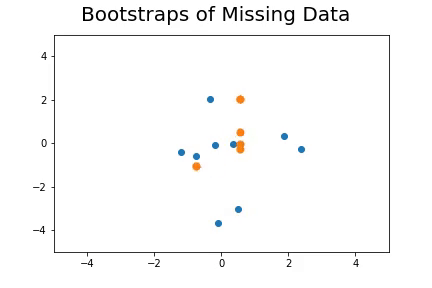
On the left we have mean imputation, on the right we have our bootstrap extended EM imputation. Results are significantly better.



Comments